RFC-333
by Darius Kazemi, November 29 2019
In 2019 I'm reading one RFC a day in chronological order starting from the very first one. More on this project here. There is a table of contents for all my RFC posts.
Messaging switching: not just for IMPS anymore
RFC-333 is titled “A proposed experiment with a Message Switching Protocol”. It's authored by Bob Bressler of MIT's Dynamic Modeling group, Dan Murphy of BBN's TENEX group, and Dave Walden of BBN's IMP group. It's dated May 15, 1972.
The technical content
In this RFC the authors propose an entirely new paradigm for the Network Control Program (NCP): a message switching protocol. This would require changes in the core Host-Host protocol that has been foundational to the ARPANET since RFC-107 in March 1971. This is still in experimental stage and is not to be construed by readers as a formal proposal or specification.
Message switching is something that has powered the ARPANET since day one, but only between Interface Message Processors. On the Host side of things, that is to say the computers that the end users actually use, the Host-Host Protocol is based on something called line switching.
Line switching is when you open a line of communication between two points in a communcation system. When the line is being used, it is reserved and cannot be used by anyone else. When the number of lines that you have available to you are limited (as in the case of ARPANET with its 256 lines, or “links” in Network Working Group lingo), you run into massive problems with scaling communication and avoiding a traffic jam situation where all the useful lines are tied up while other lines lay empty.
As reported in RFC-317, ARPANET links 192, 193, 194, and 195 have been reserved for use in “the Message Switching Protocol experiment”. This RFC contains the results of that experiment.
Dave Walden's RFC-62, “A System for Interprocess Communication in a Resource Sharing Computer Network”, is listed as required reading before someone dives into this RFC. In that paper, which is truly one of my favorite computer science papers I've ever read, Walden lays out what interprocess communication (aka communication between programs) looks like on a single computer. He then generalizes it to a distributed set of computers, with individual processes running on individuall computers, with a Network Controller acting as a kind of operating system supervisor in between them all.
This RFC states that the Message Switching Protocol “is essentially a generalization of the interprocess communication system outlined in Section 3” of RFC-62.
The paper lays out a vision where communication happens like so:
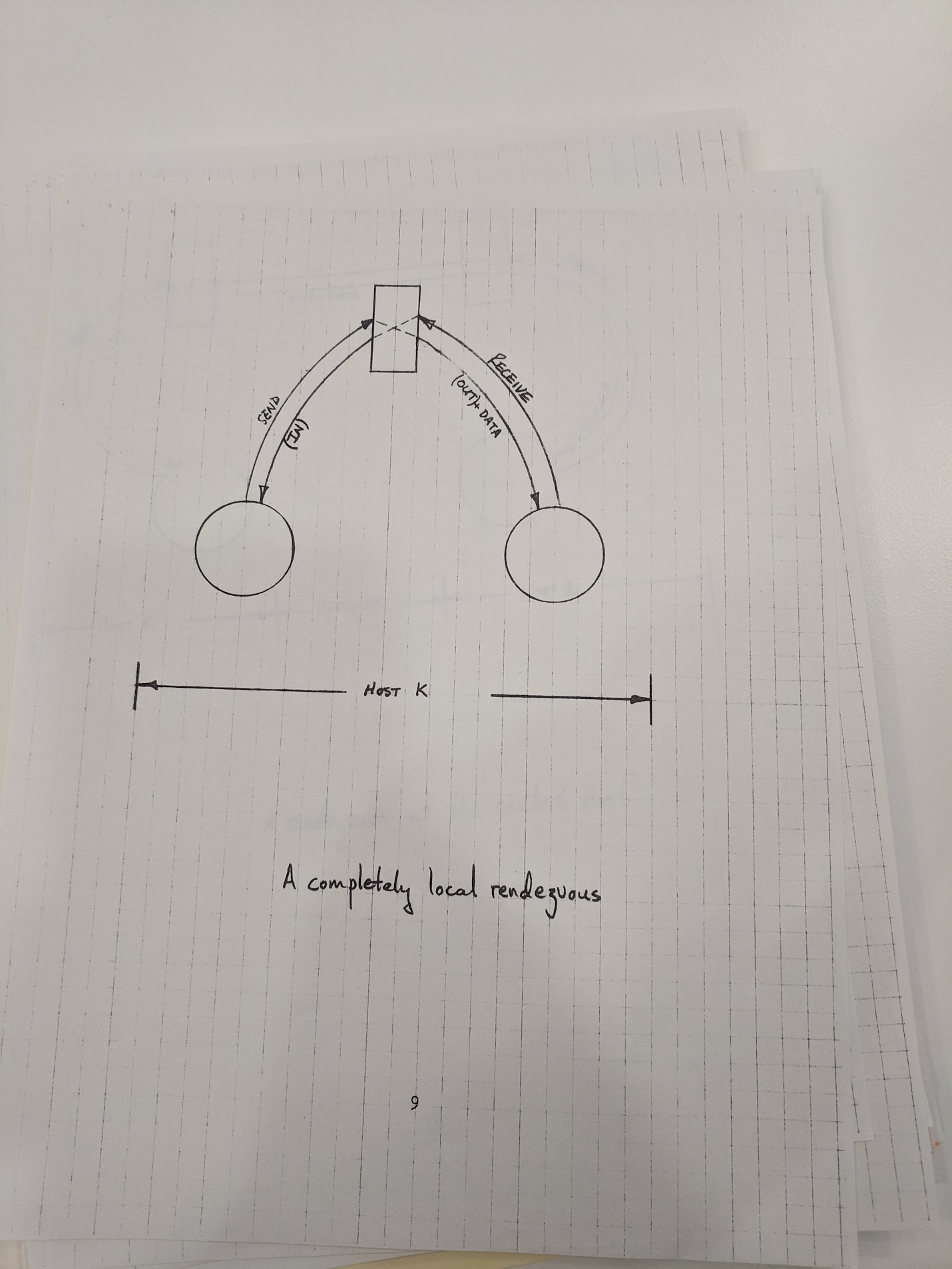
- the sender sends to a “rendezvous host” (an intermediary process either on the local computer or a well-known remote computer):
- the destination port for its message
- the port the message originates from on the sender
- the receiver sends to the rendezvous host:
- the port it's expecting to get a message from
- the port it's expecting to receive a message on
The rendezvous host determines if these ports match up, and if they do, it forwards the message on to the receiver and sends an acknowledgment to the sender.
Of note is that “port” is a network-wide unique identifier, so you can think of it as the modern combination of hostname and port, rather than just the four-digit numbers we think of today. Though really it's independent of any host and can “live” on any physical computer on the network and do its job. This gives you the option to move a port from computer to computer as needed.
If your port ID is set to 0 it means “ANY”, which lets you say things to the rendezvous host like “I will receive messages from any port to this specific port”.
While the model presented here sets up the “rendezvous host” as a generic intermediary process on some generic intermediary host, the authors expect the sender to act as the rendezvous most of the time, simplifying the overall process.
The RFC includes a large section devoted to discussion of how a local computer could generate a guaranteed unique identifier. The authors postulate an “information operator” that handles all the association and routing of port IDs. It is strikingly similar to a modern DNS resolver in function, in that you can give it a symbolic identification for a foreign process and receive the port ID of the foreign process. The authors say that the information operator will operate in “RECEIVE ANY” mode on a well-known port, and that this port “could in general be the only well-known port in existence”. This is basically how DNS works today for most end users. Generally speaking the only time you ever have to know a specific IP address is when you put the IP address of your DNS service into network settings.
There is a diagram missing from the canonical online version of the RFC, illustrating a “completely local rendezvous”. I snapped a photo at the Comptuer History Museum and have supplied it here.
Analysis
What this all means is that you no longer have to reserve a physical link to communicate between two different hosts. You just say “here is my message, I want to send it to this location, please get it there”. Again, this is how the IMP network internally always worked (this is why BBN's IMP is considered the birth of the practical packet-switched network) but to date the Host-Host Protocol has not worked this way. You needed to know both your destination and reserve a path to get there.
The scheme discussed in this paper works more like the modern internet than anything we've seen in the RFC series so far.
This RFC, while it has three authors, has Walden's stamp all over it, including little asides like this one:
(Don't panic now about buffering in an intermediate Host. The time to panic is afer you've read and understood the rest of our arguments.)
How to follow this blog
You can subscribe to this blog's RSS feed or if you're on a federated ActivityPub social network like Mastodon or Pleroma you can search for the user “@365-rfcs@write.as” and follow it there.
About me
I'm Darius Kazemi. I'm an independent technologist and artist. I do a lot of work on the decentralized web with ActivityPub, including a Node.js reference implementation, an RSS-to-ActivityPub converter, and a fork of Mastodon, called Hometown. You can support my work via my Patreon.