RFC-55
by Darius Kazemi, Feb 24 2019
In 2019 I'm reading one RFC a day in chronological order starting from the very first one. More on this project here. There is a table of contents for all my RFC posts.
Squishy amoebas
RFC-55 is by Newkirk, Kraley, Postel, and Crocker. This is the same set of authors as RFC-54 but in reverse order; I assume they are using academic convention and as such it's the Harvard group that is the primary author of this RFC. But maybe not! I could easily imagine the group just agreeing to swap author positions between the two RFCs for the sake of equity. It's dated June 19th, 1970 and titled “A Prototypical Implementation of the NCP”.
The technical content
This document is an example implementation of a Network Control Program. Basically it's the program on the HOST machine that negotiates between the network and the operating system.
This document is emphatically NOT a specification.
There is, of course, absolutely no requirement to implement anything which is contained in this document. The only rigid rules which an NCP must conform to are stated in NWG/RFC#54. This description is intended only as an example, not as a model.
This is because the authors can't know what the internals of every single computer that attempts to connect to ARPANET will look like. But they feel it is a good idea to at least provide an example that people could look to. (And they are right.)
They define a set of basic assumptions about the computer they are describing in this paper. This theoretical computer is a time-shared computer with multiple users. Individual programs are run by specific users. Programs have their own internal “ports” for data to flow in and out (for example, a port might connect a program to a file in memory so it can write to that file). A port can have a socket attached to it; this socket is the port's interface to the network.
Next they define a set of pseudocode type commands for the NCP. Things like CONNECT my socket to a foreign socket, TRANSMIT data over the connection, CLOSE the connection. These are defined in a fairly detailed way, with arguments to the commands defined and various status codes enumerated.
Then they provide a kind of block-level system understanding (with accompanying diagram) of the NCP. There's an input buffer and an output buffer as described at length in the intro to RFC-54. There's a sub-program that interprets inputs from the network and shunts them to the right place (this is an error so do xyz with it, this is a message for the user so do abc with it). There's another sub-program that prioritizes different messages to be sent as output to the network (control messages take priority over regular data). And the system call interpreter is a sub-program that interprets input from the local user and does various things with it.
Next they provide descriptions of the data tables for the program, outlining how important data about the network is stored by the NCP. This includes records of which links are free to use, which HOSTs are online, which connections are active, etc. You may recall from my RFC-44 post that Edgar Codd of IBM was in the process of inventing the modern relational database at this time. This kind of thing in a modern system would be stored in a database, but here it just lives in a series of data structures (a small difference but worth noting for historical context).
Analysis
Of note is a note in the document that says “[s]quishy amoeba-like objects” (!!!) in the diagram represent component programs. The amoeba-like objects were transcribed as boxes in the RFC transcription process, but here are my photos of the two accompanying diagrams for the RFC. These are from my visit to the archives of the Computer History Museum.
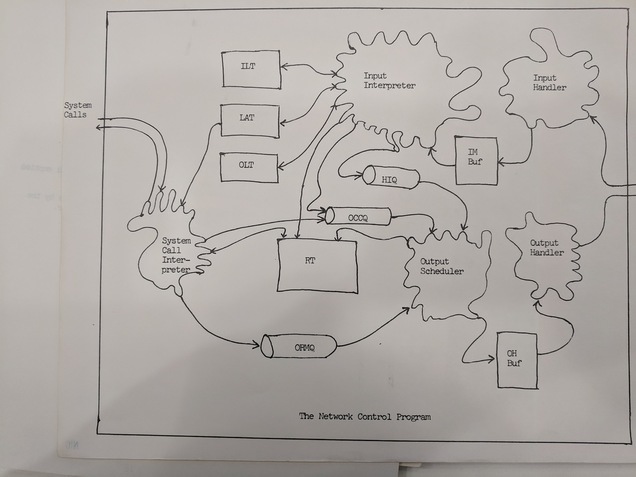
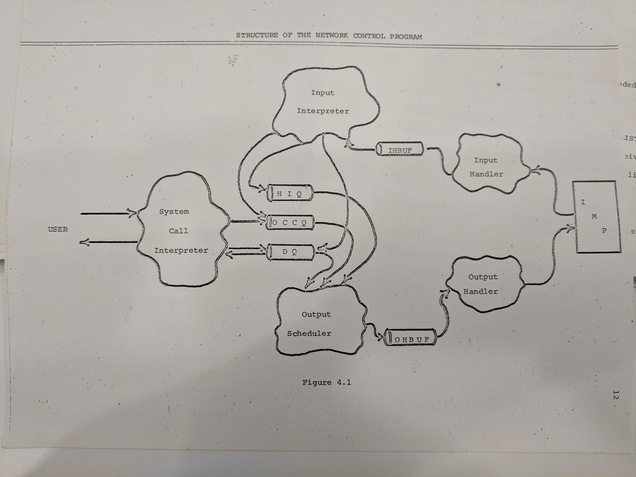
I've been fascinated by the biological nature of many of these early internet drawings. I was almost wondering if I was projecting my interpretations onto the drawings but right here in the document the original authors claim the figures are “squishy” and “amoeba-like”! I assume this is to show that these programs have indefinite conceptual boundaries, whereas the queues are a well-defined data structure and as such get a well-defined shape.
I've also noticed that some time in the past maybe ten RFCs, the writing convention has changed and what was once a HOST (all caps) is now known as a Host (title case). I will probably use Host from here on to keep parity with the convention for the documents.
How to follow this blog
You can subscribe to this blog's RSS feed or if you're on a federated ActivityPub social network like Mastodon or Pleroma you can search for the user “@365-rfcs@write.as” and follow it there.
About me
I'm Darius Kazemi. I'm a Mozilla Fellow and I do a lot of work on the decentralized web with both ActivityPub and the Dat Project.