 Choirless Alpha Release
Choirless Alpha Release

So, last night was the culmination of about eight weeks of work on a side project I've been working on called “Choirless” as part of a IBM-led competition called Call for Code. You might have seen me mention it a few times on Twitter.
Call for Code
Call for Code is about getting teams of developers together to tackle some of the major problems we face on this planet. For the last three years it has been about climate change. This year, as you'd imagine, there is a track for COVID-19. Not trying to 'cure' COVID-19 (IBM are doing work elsewhere in helping with that) but more to do with the effects of isolation on us. Remote education, community cohesion, crisis communication.
In fact, I had even started writing a draft post about Choirless back at the start, but never got a chance to finish the post as was so busy working on the development!
This is the only bit from that post from the depths of my drafts folder that makes sense to salvage. It is about a kick-off event in the UK for Call for Code:
I had an inkling of an idea before the event started: a tool to enable “virtual choirs” — inspired by my 9 year old daughter. I originally wrote the idea up a few weeks prior and floated it by some colleagues to get their input, which was overall pretty positive. So the day before the UK labs challenge I started asking about on the various internal Slack channels as IBM if anyone wanted to join me. I was originally thinking that no-one would and I'd be building it myself... but then up popped Glynn and Sean. I know Sean as I've recently joined the London City Developer Advocacy team at IBM. Glynn I'd never met, but had heard his name a lot from colleagues. And so the night before a team of three of us was suddenly formed.
We actually won that internal UK Labs Call for Code competition, and set our sights on the global competition.
What is Choirless?
Choirless is a musical collaboration platform built to enter Call for Code 2020. It allows music groups to create a video wall recording of a piece of music, where all of the individual submissions are captured separately on the performers' phone, tablet or laptop.
Choirless came about during the 2020 Covid-19 Pandemic, as countries went into lockdown and social-distancing prevented choirs, bands and other musical ensembles from meeting and performing in person. Video meeting platforms such as Zoom and WebEx proved useless for live collaboration because of the network latency and the audio being optimised for speech.
Choirless aims to make it very easy for choir leaders create songs made out of several parts (e.g. alto, tenor, soprano) and to organise choir members to provide renditions of a part. All of the contributed videos are stitched together into an video wall with no special equipment and without employing costly and time-consuming video editing software.
Alpha Release and Competition Submission
Fast forward eight weeks and I can announce that, on the day before the competition deadline, we just launched the first “alpha” release of it. That is, we did a private test in which we invited IBM colleagues and friends to take part in a virtual choir to sing “Yellow Submarine”.
Below is the video we created and submitted as part of our entry to the competition.
The Performance
It was the penultimate day before we had to submit out entry for the competition. We suddenly had a bold, crazy idea... lets do an actual performance. We've just about got the system working, lets test it with actual people all the way through.
So far we'd tested various parts of the system, and we knew they worked. But we'd yet to test the entire thing end-to-end. Letting real users loose on the site to record their own renditions, and submit them. And have the servers convert, process, synchronise and stitch the pieces together with no human interaction at all.
Anyone who has worked on this sort of thing before know this is where the problems lie. You think it all works and then someone comes along with a different web browser, or a different computer, or does something totally unexpected and it all fails.
If it worked, we'd have some up to date material for our submission video (above), and if it failed we'd no doubt learn a load of things and still have a fallback for the submission.
Sure enough, that evening we discovered a bug. For some reason audio was being heavily compressed and sounding awful. We had no idea why all of a sudden. Sean, who knows more than anyone should, about video recording in web browsers, stayed up working on it that evening. Just before we were all about to go to bed “I think I've got it!” he wrote. And posted a video at 11pm of him on his ukulele in glorious full-quality sound.

So we were back in action again. We agreed to wipe the database clean from all the testing data that night, and first thing in the morning Glynn was going to get his guitar and record a new reference track for us to sing to. I had an interview in the morning with a copywriter who was writing a piece on Choirless.
Morning came of the final day.
Glynn uploaded his guitar pieces at 9am, and his vocal part. I recorded mine once I'd finished the interview, and Sean uploaded his. Just the three of us...

We announced everything on Slack at work, and tried to cajole as many people in as we could. I'd set up a notification system that would post update into the Slack channel as pieces were uploaded.
Nothing.
No-one contributed.
Oh crap :( Why not? Have we misjudged this?
Then at exactly 4pm...

Our colleague Angela had a go. And contrary to her assessment, her singing was perfect. And even added in a dolphin on a stick part way through. In just two minutes the system had taken Angela's contribution and added it to the mix.
Then 10 minutes later, not just one, but two came in at the same time. Daniel and Steve.

Then another. And another. And suddenly someone with a recorder. Then a clarinet. Someone working from their shed. Someone got their wife and kids involved. Then someone played the drums...
It. Was. Working.
The slack status monitor was showing each new part as it came in live. And three minutes later we'd get a new rendering. This was a living performance evolving in front of our eyes.
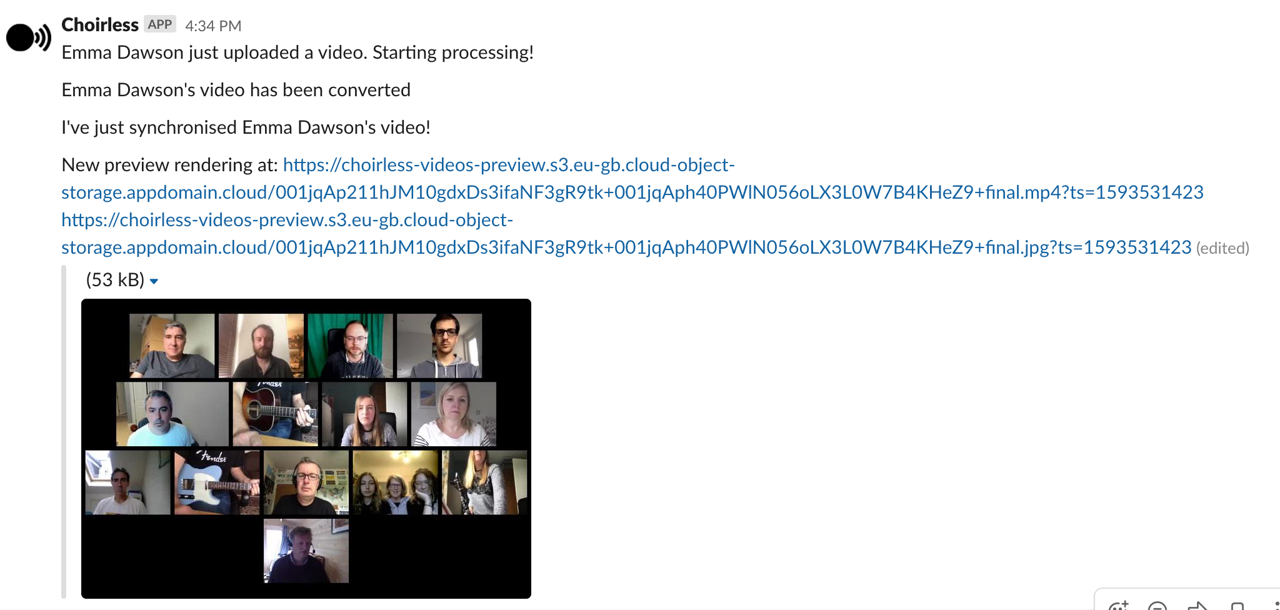
Absolutely elated, Sean, Glynn and I were polishing off the last bits of the submission. Tidying up the codebase on Github, making sure we had README files for everything. We had to create a roadmap document showing where we were going. I edited the performance from that day into our submission video. Even whilst people were adding more to the performance!

And finally that evening, after checking things over for a third time, I hit submit.

This truly has been a project that has been more than the sum of its parts. Having, almost randomly, found Sean and Glynn, I can honestly say that this project would not be anywhere near as good without the contributions from all three of us.
So, Onwards! The submission is done. Our fingers are crossed we win. But development continues. We hope to have a public beta out for people to try themselves in the next month.
If you want to read more about the technical details of Choirless, and the technology behind it (including some great services from IBM Cloud) you can on our development mini-site:
And for Coil subscribers, below is the full video of the performance.














