Improving the qcolor-from-literal Clazy check
For all of you who don't know, Clazy is a clang compiler plugin that adds checks for Qt semantics.
I have it as my default compiler, because it gives me useful hints when writing or working with preexisting code.
Recently, I decided to give working on the project a try! One bigger contribution of mine was to the qcolor-from-literal check, which is a performance optimization.
A QColor object has different constructors, this check is about the string constructor. It may accept standardized colors like “lightblue”, but also color patterns.
Those can have different formats, but all provide an RGB value and optionally transparency. Having Qt parse this as a string causes performance overhead compared to alternatives.
Fixits for RGB/RGBA patterns
When using a color pattern like “#123” or “#112233”, you may simply replace the string parameter with an integer providing the same value. Rather than getting a generic warning about using this other constructor, a more specific warning with a replacement text (called fixit) is emitted.
testf4ile.cpp:92:16: warning: The QColor ctor taking RGB int value is cheaper than one taking string literals [-Wclazy-qcolor-from-literal]
QColor("#123");
^~~~~~
0x112233
testfile.cpp:93:16: warning: The QColor ctor taking RGB int value is cheaper than one taking string literals [-Wclazy-qcolor-from-lite
QColor("#112233");
^~~~~~~~~
0x112233
In case a transparency parameter is specified, the fixit and message are adjusted:
testfile.cpp:92:16: warning: The QColor ctor taking ints is cheaper than one taking string literals [-Wclazy-qcolor-from-literal]
QColor("#9931363b");
^~~~~~~~~~~
0x31, 0x36, 0x3b, 0x99
Warnings for invalid color patterns
Next to providing fixits for more optimized code, the check now verifies that the provided pattern is valid regarding the length and contained characters. Without this addition, an invalid pattern would be silently ignored or cause an improper fixit to be suggested.
.../qcolor-from-literal/main.cpp:21:28: warning: Pattern length does not match any supported one by QColor, check the documentation [-Wclazy-qcolor-from-literal]
QColor invalidPattern1("#0000011112222");
^
.../qcolor-from-literal/main.cpp:22:28: warning: QColor pattern may only contain hexadecimal digits [-Wclazy-qcolor-from-literal]
QColor invalidPattern2("#G00011112222");
Fixing a misleading warning for more precise patterns
In case a “#RRRGGGBBB” or “#RRRRGGGGBBBB” pattern is used, the message would previously suggest using the constructor taking ints. This would however result in an invalid QColor, because the range from 0-255 is exceeded. QRgba64 should be used instead, which provides higher precision.
I hope you find this new or rather improved feature of Clazy useful! I utilized the fixits in Kirigami, see https://invent.kde.org/frameworks/kirigami/-/commit/8e4a5fb30cc014cfc7abd9c58bf3b5f27f468168. Doing the change manually in Kirigami would have been way faster, but less fun. Also, we wouldn't have ended up with better tooling :)

 Profiling of the unoptimized version, loading the correct Icon takes a large porting of CPU cycles
Profiling of the unoptimized version, loading the correct Icon takes a large porting of CPU cycles
 Optimized version, CPU cycles are significantly reduced and loading of icons is barely distinguishable from other, minor costs
Optimized version, CPU cycles are significantly reduced and loading of icons is barely distinguishable from other, minor costs Profiling excerpt from the match-method, which produces results for your typed query
Profiling excerpt from the match-method, which produces results for your typed query Profiling excerpt from all plugins being loaded (main thread)
Profiling excerpt from all plugins being loaded (main thread) AFTER:
AFTER:
 AFTER:
AFTER:
 The view of the city from the hotel balcony was also quite nice
The view of the city from the hotel balcony was also quite nice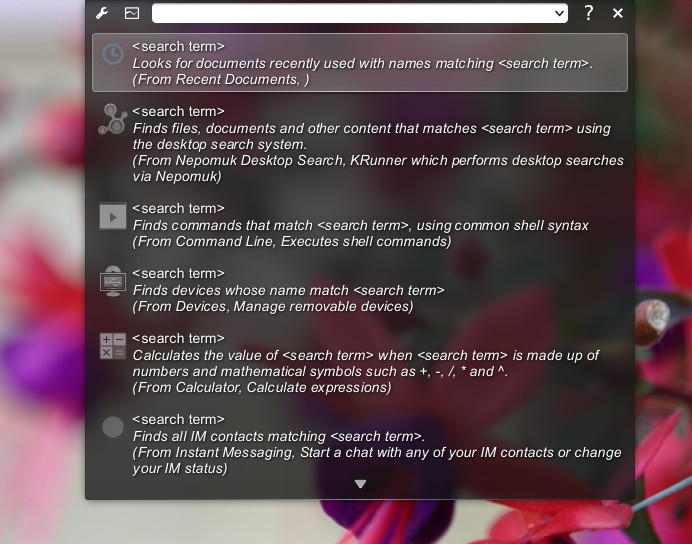 Since the help system required reimplementation, it was decided to implement it as a plugin for KRunner's powerful plugin infrastructure.
This plugin produces results when one types
Since the help system required reimplementation, it was decided to implement it as a plugin for KRunner's powerful plugin infrastructure.
This plugin produces results when one types  By having it as a plugin it is reusable in every case KRunner is used,
for example the KWin overview effect, the Application Launcher or the Plasma-Mobile search.
By having it as a plugin it is reusable in every case KRunner is used,
for example the KWin overview effect, the Application Launcher or the Plasma-Mobile search. Otherwise you would have needed to click the configure button on the left, search for the runner and
then click the configure button for the specific runner.
Otherwise you would have needed to click the configure button on the left, search for the runner and
then click the configure button for the specific runner.
