by Darius Kazemi, Feb 23 2019
In 2019 I'm reading one RFC a day in chronological order starting from the very first one. More on this project here. There is a table of contents for all my RFC posts.
A proffering
RFC-54 has a whopping four authors. To date we've seen a maximum of two listed on one RFC. They are: Steve Crocker, Jon Postel, and two newcomers to the series, John Newkirk and Mike Kraley of Harvard. Recall that Harvard was added to the distribution list in RFC-52. This is dated June 18, 1970 and titled “An Official Protocol Proffering” (say that five times fast).
The technical content
This is the promised first-ever attempt at an official protocol being published as an RFC. Per the rules laid out in RFC-53, they give a deadline for comment of July 13th 1970, a little less than a month after the date of this RFC (so probably about 3 full weeks for people to respond once they've received this RFC in the mail).
The first section is an overview and defense of the concepts in the document.
They have decided to single out “only network-wide issues” for an official standard that people will be forced to adopt. They still want to let everything on the HOST side be as open to interpretation as possible. As long as you speak the lingua franca of the ARPANET in public, the ARPANET doesn't care what language you use at home.
In the course of designing this current protocol, we have come to understand that flow control is more complex than we imagined.
By “flow control” they mean controlling network traffic so it doesn't get backed up. I was wondering why they seemed to assume up to this point that it would be a trivial solution; of course I am reading these documents with literally half a century of hindsight. Now we finally see them bump into these problems.
The basic proposal is that when a HOST A wants to send data to HOST B, it is up to B to maintain a memory buffer and let A know how much buffer space remains. And A is supposed to respect that. A physical analogy: suppose you want to ship 1000 crates of goods to a warehouse, but they have a limited number of storage bays. So you say “I want to send you 1000 crates of goods” and they reply “we only have room for 50 crates today”, and then you decide whether to send them 50 crates or just cancel sending entirely because it's not worth it to you.
The authors claim that this algorithm simplifies some of the existing designs for flow control, so there will be fewer commands over the network to keep track of. They would like to keep this initial version of flow control as simple as possible, even at the cost of being probably too conservative in how much data is sent over the network. They are open to future protocols that are more complex but I get the sense that they just want this thing to ship, you know?
They also propose two meetings, one at UCLA and one at Harvard, for people to attend with any questions they have about the protocol. They specify that they want at most one programmer from each institution to attend.
The second section is more of a technical specification.
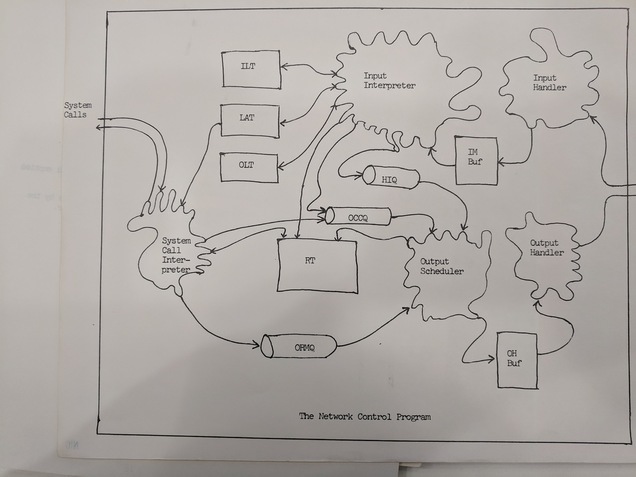
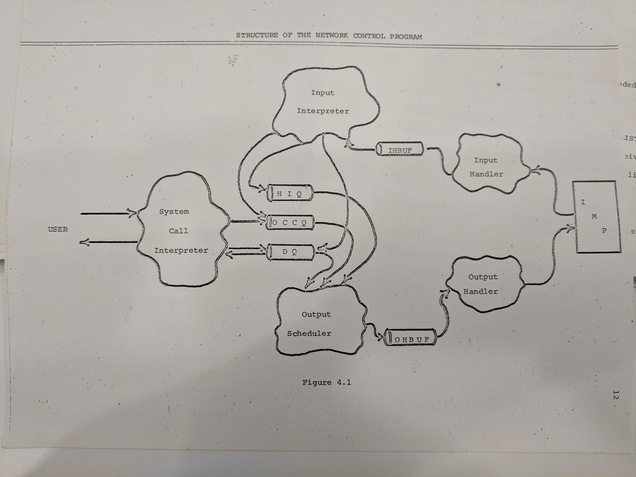
First they define a “connection” as “a simplex communication path [...] between two processes”. In other words, a connection is a one-way flow of data between two different computer programs over the network.
The main purpose of this protocol is to establish how connections are created, how flow control is to work in an open connection, and how they are terminated.
The way a connection is opened is through two “sockets”. A socket has a unique ID known throughout the network and corresponds to a particular program running on a particular HOST. You open a connection saying “I want this socket to connect to that socket”, which is another way of saying “I want this program on my computer to connect to that program on your computer.” (A close analogue to a socket today would be a combination of an IP address and a port number.)
Every connection gets its own link. This is in contrast to earlier proposals of “multiplexing systems” (like RFC-38) where multiple connections could share the same link. (Maybe you recall from my RFC-11 post that multiplexing is when you combine one or more signals in such a way that you can send them over the same communication channel but detangle them from one another on receipt.)
When a socket is in use it is reserved. Basically only one program can't talk to multiple other programs on the network at the same time. Connections and their attendant sockets are one-to-one.
The final section lays out some more general thoughts.
They identify three areas where future protocols might improve on this one: better flow control, error handling, and what to do when a computer is only part-time connected to the network.
They “suggest that hosts come onto the network gingerly.” Specifically they recommend that a HOST talk to its own sockets first as a test mechanism; then it should talk to a HOST that is known to be working well; then it can try talking to all HOSTs. The folks at UCLA offer to be the test case for anyone who wants it.
Apparently local sites have already been using the IMP as a kind of local router! “For example, Harvard is connecting its PDP-1 to its PDP-10 via an IMP”. That's pretty cool. They beseech people doing this to use caution so as not to like, bring down the entire ARPANET by accident.
Analysis
I suspect one reason there are four authors on this is to both have a lot of eyes look at this first official specification attempt, and also to show that two very different institutions (UCLA and Harvard) are on board with it. You know, for once it's not just those zany kids Crocker and Postel at UCLA coming up with this stuff!
One question I have is: how are sockets “known throughout the network”? Partly it's by convention. Even numbered sockets are assumed to be for receiving data; odd numbered sockets are assumed to be for sending data. But beyond that I'm not sure how everyone is supposed to know about everyone else's socket IDs.
Everything about this particular protocol proposal screams “simple” to me. It's relatively easy to implement. It's not maximally efficient but it gets the job done. I like it a lot. It's frankly the first proposal I've seen here that I believe I would not have pushed back on had I been one of these original NWG members.
I sort of assumed that this kind of thing would be literally the first thing we'd see in like RFC-1, but over the past 14 months of RFCs, we have seen proposals of medium complexity (like the original HOST-HOST protocol) all the way up to extremely high complexity (DEL, NIL).
It took them more than a year to arrive at something simple!
How to follow this blog
You can subscribe to this blog's RSS feed or if you're on a federated ActivityPub social network like Mastodon or Pleroma you can search for the user “@365-rfcs@write.as” and follow it there.
About me
I'm Darius Kazemi. I'm a Mozilla Fellow and I do a lot of work on the decentralized web with both ActivityPub and the Dat Project.