by Darius Kazemi, April 11 2019
In 2019 I'm reading one RFC a day in chronological order starting from the very first one. More on this project here. There is a table of contents for all my RFC posts.
A winter meeting
RFC-101 is titled “Notes on the Network Working Group Meeting”. It's authored by Richard W. Watson of SRI-ARC and dated February 23, 1971.
A business note: my ten-month Mozilla Fellowship has supported this project up until now, but that has ended. If you like what I'm doing here, please consider supporting me via my Patreon.
The technical content
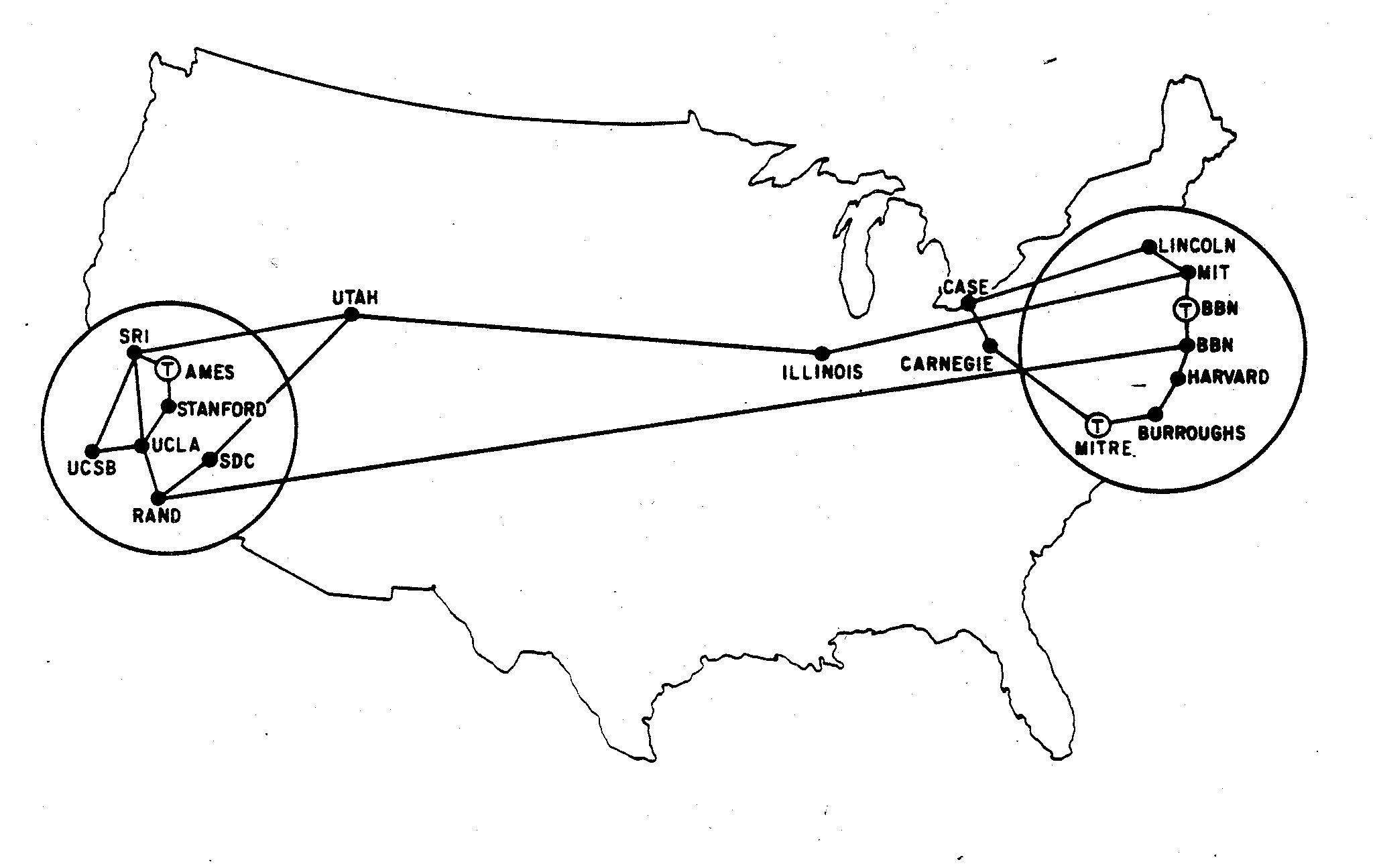
This RFC is a summary of the quarterly NWG meeting held at the University of Illinois on February 17th-19th, 1971. These quarterly meetings were formally announced in RFC-85.
There was discussion of a cool use of the ARPANET. Apparently by the spring of 1970, SRI needed to ditch their XDS 940 computer and replace it with a PDP-10. But it can take a long time to learn a new computer system, so what they did was utilize timesharing via the ARPANET to train their staff on the PDP-10 at the University of Utah! By June 1970 they were using their 940 to generate source code for the PDP-10, which they would then send to Utah over the network. Then they'd remotely run and debug those programs interactively.
At the SRI and Utah ends a control program allowing three users to connect to Utah was written, which ran as a user process and allowed character interaction and files to be transmitted. The scheme worked well and much useful work was accomplished in the July--December period with some people on 4-5 hours per day. The voice link was used when something would go wrong in trying to determine where the problem existed and to reset. At times they would go 2 weeks with no problems.
The “voice link” mentioned there is basically getting the other end of the network on the telephone to work out what was going wrong. It's like in 2019 when a video conference doesn't work and you have to call the cell phone of someone in the video conference to figure out what's going on.
Round trip character delays of 4 seconds were not uncommon, and at certain points delays of 8 or 10 minutes were experienced. These delays were the result of the implementation used which involved multiple processes at each end, each to be scheduled. Utah was heavily loaded at 2:00 PM and the SRI people took to running at night and on weekends.
So around 2pm it could take multiple minutes to talk to the computer at Utah from SRI — as a result people started doing the work on nights and weekends.
By December 1970, SRI received their PDP-10 and got to put their six months of remote work to use on an in-person computer. Pretty cool stuff.
There is mention that UCSB has teamed up with Rand Corporation to “experiment in use of the Network for the climate study at RAND”. I imagine that this is related to the work from RFC authors Harslem and Heafner that would be published by the end of 1971, VIEW: Status Report of a Computer Program for Display of Arbitrary Data Bases, which is about a remote data visualization program that according to the paper's abstract is designed “to cope with the mass of data produced by climate dynamics simulations”. More on this in “Further reading” below.
Steve Crocker says he thinks there should be working committees on important topics within the Network Working Group and proposes the following areas:
1. Graphics
2. Data Transformation Languages
3. Host-Host Protocol -- long range study
4. Host-Host Protocol -- Short term maintenance and modifications
5. Accounting
6. Logger Protocol
7. Typewriter connection protocol
8. Documentation
9. Data Management
In this context, “accounting” means “ways to track the time that people use on your computer so you can charge them money for it.” Various such committees are proposed, at least for the first 4 categories.
There is a representative of the Canadian government present at this meeting. Specifically it's C.D. “Terry” Shepard of the Canadian Computer/Communications Task Force. The task force sent a representative because Canada wants their own internet so they won't be fully dependent on foreign sources for computing resources in the future.
There is some discussion of some networking projects internal to IBM, one of which uses a “central machine for control and flow distribution”, which they “are not entirely happy” about and want to be more decentralized like ARPANET.
The meeting adjourns and then continues the following morning.
BBN gives an update on the network of IMPs, and various groups give updates to their progress on their own network control programs (NCPs).
There is also an update to the NWG mailing list procedures. Remember, this is still pre-email and still coordinated through secretaries maintaining manual lists of addresses and sending copies of memos via the postal service!
Subcommittees are formed for the above issues number 6 and 7, the logger protocol and typewriter connection protocol.
In the afternoon the University of Illinois gave a demonstration of PLATO, their famous interactive graphical learning system. (There's a modern PLATO descendant called Cyber1 and you can get a login and download the terminal program to try it out!)
In the evening the Network Information Center at SRI is discussed. As of 1971 the NIC is basically a library of documents that also is involved in network administration like maintaining hot tables. This will eventually become the organization that administers DNS in its early years. Anyway, its function as a kind of library is clear in these notes from the NIC presentation:
If the network is really going to develop the feeling of a community, people need to be aware of what people are doing and thinking at the various sites. Therefore, people were encouraged to send reports, memos, notes, records of conversations of general interest through the NIC. Any kind of information can be sent through the NIC from formal reports to informal handwritten notes.
This is followed by considerable discussion of computerized cataloguing systems and remote access to the NIC via ARPANET. This naturally becomes a discussion about file transfer protocols, which we are going to hear a lot more about in the next 100 RFCs. This all cover the “documentation” portion of Crocker's agenda.
The meeting adjourns for the day. The next morning, data management and accounting, the last unaddressed issues in the agenda, are discussed. There are a number of aspects to data management, but basically it comes down to:
- the “trillion bit store”, which is conceived as a (massive for the time) shared hard drive for the ARPANET (related paper here)
- the “form machine” for translating between data types (see RFC-83)
- a file transfer protocol of some kind
And finally they tackle accounting, AKA the process of figuring out how much money to bill users of time shared computers. This seems like everyone's least favorite subject. Bob Kahn says he'll write a paper on the issues of accounting, which I believe ends up being RFC-136.
Lastly, consensus seems to be that for future meetings, papers related to discussion areas should be sent out a month in advance so that attendees can be prepared to have more in-depth discussions than were possible this time.
Analysis
The University of Illinois at Urbana has long been one of the great American computer science powerhouse universities. The RFC opens with Mike Sher telling the group that ILLIAC IV, which according to Wikipedia is “the first massively parallel computer”, would be ready in the summer of 1971. With hindsight we know that his estimate was about a year off.
Apparently U of I has an IMP at the time of this NWG meeting, but it is not connected to their PDP-11. It was initially unclear to me whether this means it's not connected to anything at all though. If we look at BBN Report No. 2103 from January 1971 (one month before this meeting) we see on page 11 that Illinois is reported as connected, BUT that is only a report on their IMP having been installed and connected, and nothing to do with whether it's actually in use.
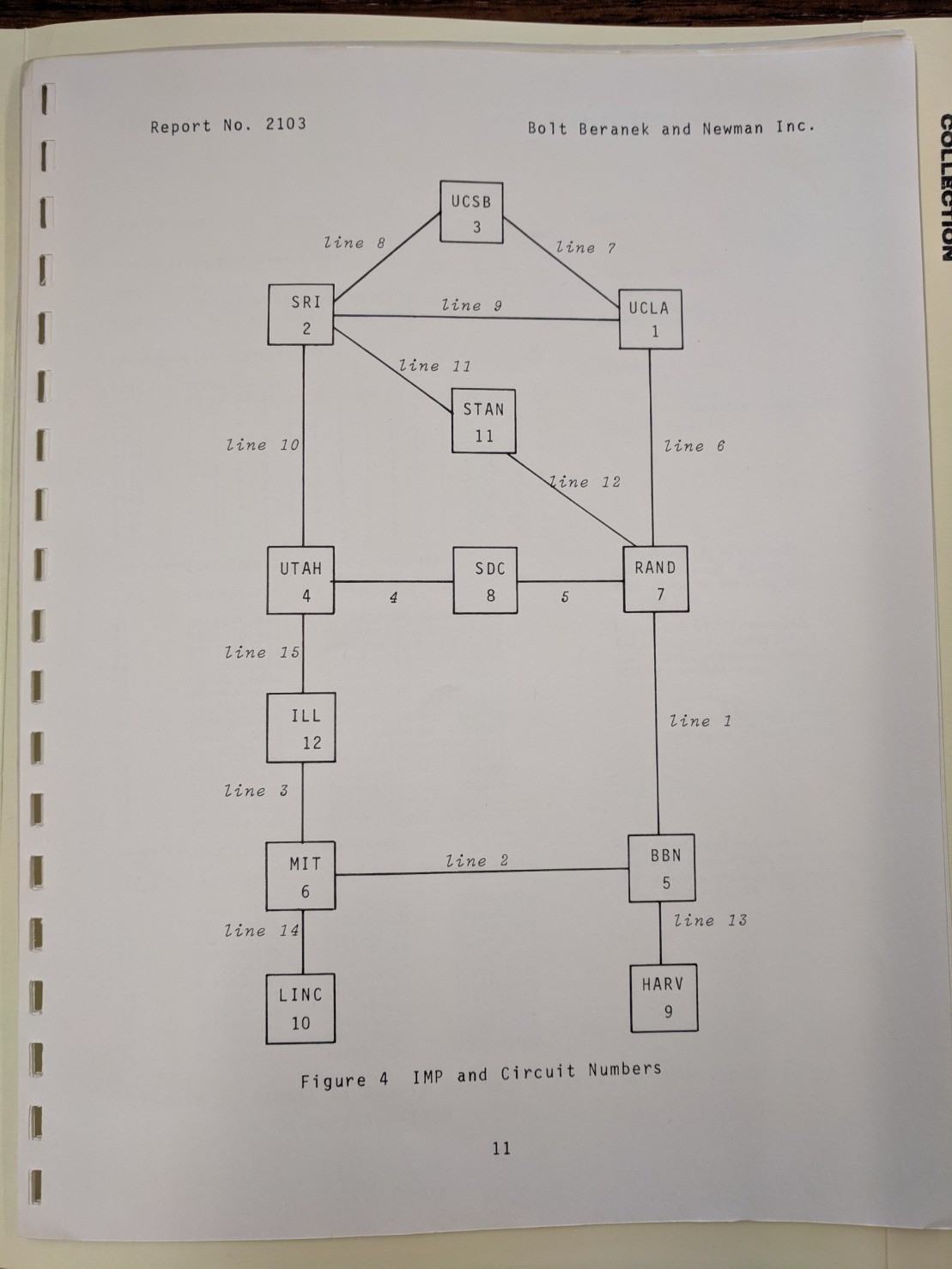 .
.
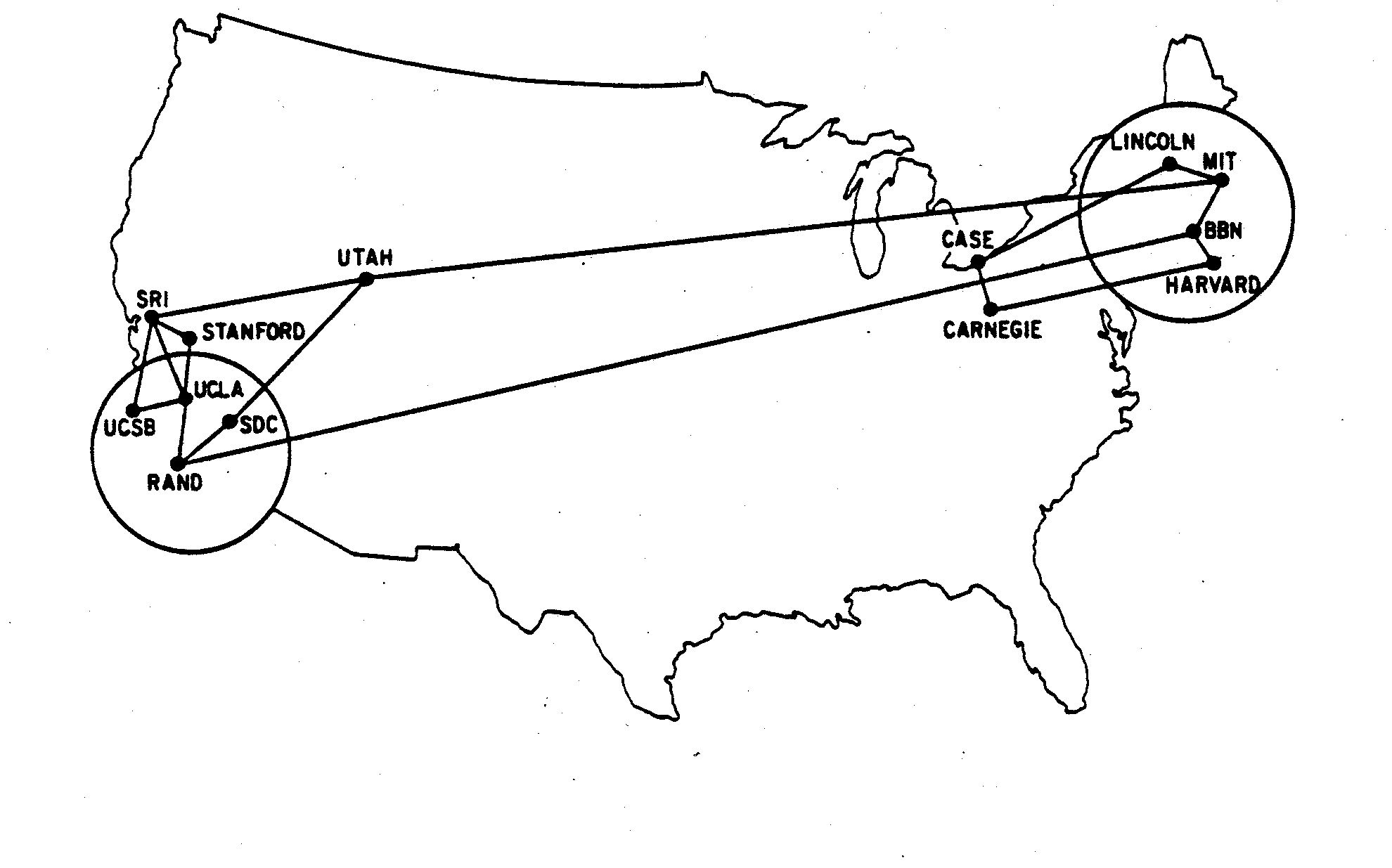
This December 1970 ARPANET map shows Illinois is not connected, and a September 1971 ARAPNET map shows that they are. So presumably at the time of the meeting the IMP at Illinois was not in use by the U of I, though according to BBN's reports it was already routing packets to and from Utah and MIT.
Further reading
Since there was mention of Rand Corporation's climate studies, I thought I'd link to a few fascinating ones that you can read the full text of for free.
Studies in Climate Dynamics for Environmental Security by R.C. Alexander, September 1970. This is a paper about responding to adversarial geoengineering and how we might predict the ways that climate change could affect the weather! (Turns out, the call was mostly coming from inside the house.)
A Model of Global Climate and Ecology is a heavily cited paper by Graham and Warshaw, also dated September 1970, that lays out some of the first mathematical models for global climate.
The Statistical Analysis of Simulated Climatic Change by M. Warshaw, September 1973, lays out some ways that you might be able to determine whether changes in global climate are the result of random fluctuation or are the result of some kind of anthropogenic (intentional or unintentional) source.
For more context on the Canadian Computer/Communications Task Force, you can read this really interesting 1994 article by Bernard Ostry that is highly critical of Canada's internet and telecommunications infrastructure. He says of the Task Force that it
reported its findings in 1972 in a two-volume study entitled Branching Out. The Task Force offered 39 recommendations and some suggestions. Action was taken in four cases, and begun in five others which were discontinued. Twenty-four recommendations appear to have been ignored, despite a green paper which followed about a year later commending the importance of the report.
I'd love to find a copy of “Branching Out”, but I can't find any scans online. I may need to head to Ottawa to get my hands on a hard copy...
How to follow this blog
You can subscribe to this blog's RSS feed or if you're on a federated ActivityPub social network like Mastodon or Pleroma you can search for the user “@365-rfcs@write.as” and follow it there.
About me
I'm Darius Kazemi. I'm an independent technologist and artist. I do a lot of work on the decentralized web with both ActivityPub and the Dat Project. You can support my work via my Patreon.
{kind=link}
{kind=link}