Proposition de faire passer sa publicité dans le Figaro
Le 23 septembre, je reçois (sur une adresse personnelle) un spam venant d'une entreprise de spam (l'émetteur SMTP est publi-redactionnel.deltapresse.fr / 77.32.194.137) et me proposant EN CRIANT « PROPOSITION D'UN PUBLIREPORTAGE DIFFUSÉ SUR LE FIGARO ». Le texte prétend que « Le tournage se déroule dans le studio du Figaro au 14 Boulevard Haussmann à Paris 9ème » et que « Vous bénéficiez des audiences du Le Figaro , premier site d’information en France, disposant d'une cible qualifiée aux quatre coins de l'Hexagone. (Note de ma part : À mon avis, un hexagone a six coins, mais passons.) Cette émission est préparée en amont avec notre présentateur « Itinéraire Entreprise ». C'est donc vous qui choisissez les sujets que vous souhaitez aborder lors de l'entretien. L’objectif ? Promouvoir votre société, votre savoir-faire et vos compétences. Grâce à cette interview vidéo, vous pourrez communiquer en misant sur votre personnalité et être vu partout et tout le temps. »
Il s'agit bien de publicité, pas d'un reportage : « Préparation : Notre présentateur “Itinéraire Entreprise” vous contacte une semaine avant pour préparer l'interview en amont. Cet exercice vous permet d'anticiper les questions pour vous sentir plus en confiance lors du tournage » et pour faire plus pro « Transport : Un chauffeur est à votre disposition pour vos trajets à Paris intramuros et vous emmène directement dans les locaux du Figaro Boulevard Haussmann. Maquillage : À votre arrivée, une hôtesse d'accueil vous reçoit et vous accompagne dans la loge pour une séance de maquillage en accord avec la lumière du plateau. »
Le résultat : on sera connu « Photo : Des clichés professionnels sont capturés pour la création de visuels sur vos réseaux sociaux. Interview : Une prise de parole est opérée face caméra avec notre présentateur. Rédaction : Un article de 750 mots récapitulatif est rédigé par notre attachée de presse. Il comprendra vos coordonnées ainsi que trois liens vers votre site internet et vos réseaux sociaux. Relais digital : Notre partenaire Delta Presse diffuse votre article à un panel de plus de 95 000 journalistes pour un relais sur différents médias. (Note de ma part : J'en profite pour vous recommande les savoureux tweets d'un journaliste spécialisé en informatiuqe qui se moque des innombrables communiqués de presse débiles qu'il reçoit, mot-croisillon CommuniquéIdiotDuJour sur Twitter.) Publication : La vidéo et l'article sont diffusés sur la page économie du Le Figaro. Une page web sur le Le Figaro hxxps://www.lefigaro.fr/economie/dossier/itineraire-entreprise ) vous sera complètement dédiée. Tracking (Note de ma part : comme c'est mignon, comme terme : les spammeurs n'ont pas honte de dire qu'ils fliqueront les visiteurs, par exemple avec des web bugs.) : Un suivi de l'audience de votre interview est réalisé par nos soins. Vous bénéficierez d'un taux de rebond et d'un référencement efficace grâce à l'interview et de ces liens dont raffole Google. Une fois diffusée, vous recevrez une copie de cette interview pour votre site internet et vos propres réseaux sociaux. »
À aucun moment, ils ne parlent du prix que cela me coûtera si j'étais assez bête et assez vaniteux pour accepter.
J'ignore si le Figaro est vraiment impliqué, je vais leur demander.
 Mais certaines applications font bien pire, en envoyant d'autres données, parfois plus sensibles.
Pourquoi tant de développeurs ont-ils choisi d'envoyer ces données à Facebook ? Parfois, c'est tout simplement qu'ils ne le savaient pas. Ils avaient inclus le SDK (Software Development Kit, la bibliothèque logicielle que Facebook fournit à ceux qui veulent inclure certains services Facebook dans leur app) et le SDK, dès le démarrage de l'application, envoie les données à Facebook, avant toute demande d'autorisation. (Notez qu'Exodus Privacy avait déjà noté un problème similaire : des développeurs informatiques négligents incluent une bibliothèque dans leur app, sans vérifier si elle ne comprend pas des pisteurs.)
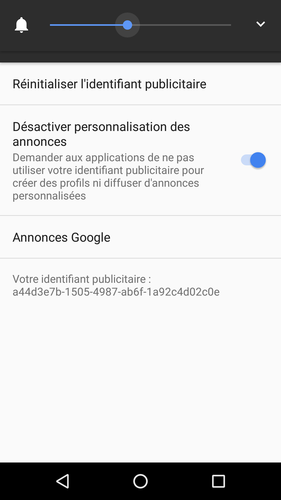
Je vous laisse lire le rapport complet, très bien fait, pour voir l'ampleur des dégueulasseries (le mot n'est pas trop fort) commises par Facebook et ses complices. Une partie très intéressante est celle qui contient les réponses des sociétés mises en cause, que Privacy International avait prévenues. Un festival de langue de bois corporate, plein de « your privacy is important to us », « we work very hard to improve the user experience », « we are committed to comply » et autres mensonges. Très peu d'entreprises répondaient concrètement, très peu annonçaient des mesures précises. La palme revient à Google qui prétend que l'identificateur publicitaire est changé lorsqu'on réinitialise l'ordiphone Android aux valeurs d'usine (cassant le suivi de l'utilisateur) alors que l'équipe de Privacy International a pu vérifier que c'était faux. On voit là le poids à accorder aux déclarations, aux privacy policies et autres promesses.
Facebook annonce quand même que le SDK a été modifié (un mois après l'entrée en application du RGPD) pour ne plus envoyer d'informations sans demande explicite de l'app. Cela ne concerne que les apps qui seront créées, dans le futur, avec le nouveau SDK. Mais pour le reste, Facebook refuse toute responsabilité, puisque les conditions d'utilisation du SDK précisent que c'est au(x) développeur(s) de l'app d'obtenir un consentement de l'utilisateur...
Bref, on voit qu'une entreprise comme Facebook est au-delà de toute possibilité de réforme, et qu'elle doit être détruite.
Mais certaines applications font bien pire, en envoyant d'autres données, parfois plus sensibles.
Pourquoi tant de développeurs ont-ils choisi d'envoyer ces données à Facebook ? Parfois, c'est tout simplement qu'ils ne le savaient pas. Ils avaient inclus le SDK (Software Development Kit, la bibliothèque logicielle que Facebook fournit à ceux qui veulent inclure certains services Facebook dans leur app) et le SDK, dès le démarrage de l'application, envoie les données à Facebook, avant toute demande d'autorisation. (Notez qu'Exodus Privacy avait déjà noté un problème similaire : des développeurs informatiques négligents incluent une bibliothèque dans leur app, sans vérifier si elle ne comprend pas des pisteurs.)
Je vous laisse lire le rapport complet, très bien fait, pour voir l'ampleur des dégueulasseries (le mot n'est pas trop fort) commises par Facebook et ses complices. Une partie très intéressante est celle qui contient les réponses des sociétés mises en cause, que Privacy International avait prévenues. Un festival de langue de bois corporate, plein de « your privacy is important to us », « we work very hard to improve the user experience », « we are committed to comply » et autres mensonges. Très peu d'entreprises répondaient concrètement, très peu annonçaient des mesures précises. La palme revient à Google qui prétend que l'identificateur publicitaire est changé lorsqu'on réinitialise l'ordiphone Android aux valeurs d'usine (cassant le suivi de l'utilisateur) alors que l'équipe de Privacy International a pu vérifier que c'était faux. On voit là le poids à accorder aux déclarations, aux privacy policies et autres promesses.
Facebook annonce quand même que le SDK a été modifié (un mois après l'entrée en application du RGPD) pour ne plus envoyer d'informations sans demande explicite de l'app. Cela ne concerne que les apps qui seront créées, dans le futur, avec le nouveau SDK. Mais pour le reste, Facebook refuse toute responsabilité, puisque les conditions d'utilisation du SDK précisent que c'est au(x) développeur(s) de l'app d'obtenir un consentement de l'utilisateur...
Bref, on voit qu'une entreprise comme Facebook est au-delà de toute possibilité de réforme, et qu'elle doit être détruite. Ça marche, la
Ça marche, la